Open-Sourcing My AI Exoskeleton
I built this in three days with the tool that will replace me.
My MacBook restarted during a hackathon sprint. Fifteen Claude Code sessions — gone. Auth flows, payment integrations, infrastructure — wiped clean.
I could have set up tmux. Instead I started digging into Claude Code’s internals. Anthropic stores a clean session index — every conversation you’ve ever had, searchable, resumable. Within a few hours I had a working prototype: a session manager that could find and resume any Claude Code session across any project. I was building it during the hackathon, guiding Claude Code in thirty-minute bursts between my actual fintech work.
That was sprint one.
Then I watched companies raising money to fine-tune personal AI models — capture your patterns in weights, deploy a digital clone that codes like you. I’d written about this two weeks earlier. The clone approach bothered me, but I hadn’t built anything better.
So I took a second sprint. Three days.
It’s called Axon. I’m open-sourcing it today.
What I built
Axon is a developer memory system. It watches what you build, synthesises what happened, and compounds the context over time instead of losing it between sessions.
The core loop:
axon collect # gather signals — git log, file tree, session activity
axon rollup # nightly AI synthesis — what happened, what was decided, what matters
axon morning # conversational briefing — where you are, what to focus onSignals in, rollup out. The AI reads what happened, folds it into what it already knows, and tells you where you stand.
Every rollup captures decision traces: what the input was, what constraints existed, what tradeoffs were weighed, what was decided. These compound over time into a searchable history of why your project looks the way it does — across every rollup, every decision.
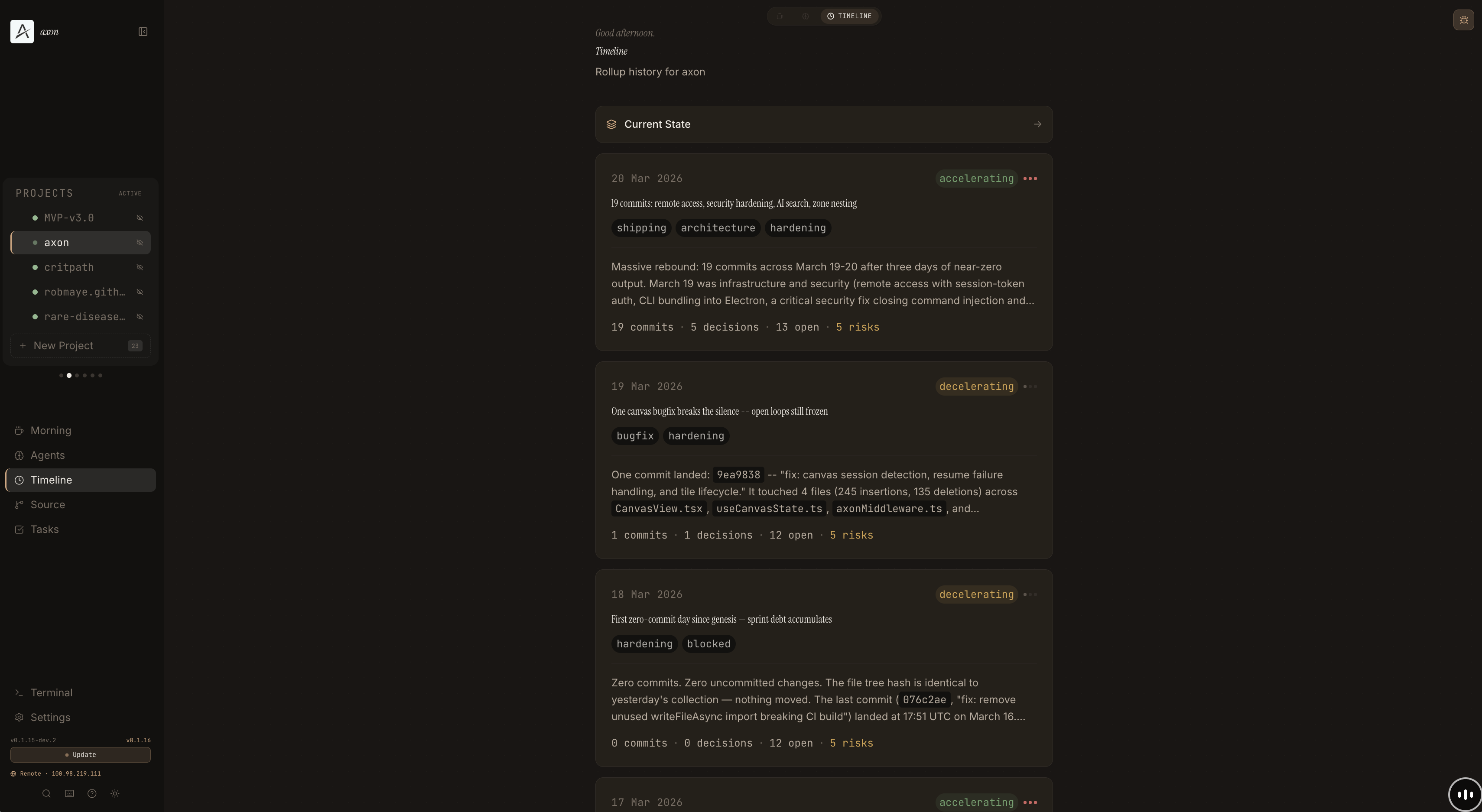
The CLI is a dozen shell scripts. Zero dependencies beyond bash, jq, git, and Claude Code. Clone the repo, run axon init on a project directory. Install a nightly cron with axon cron install and forget about it. Every morning, your briefing is waiting.
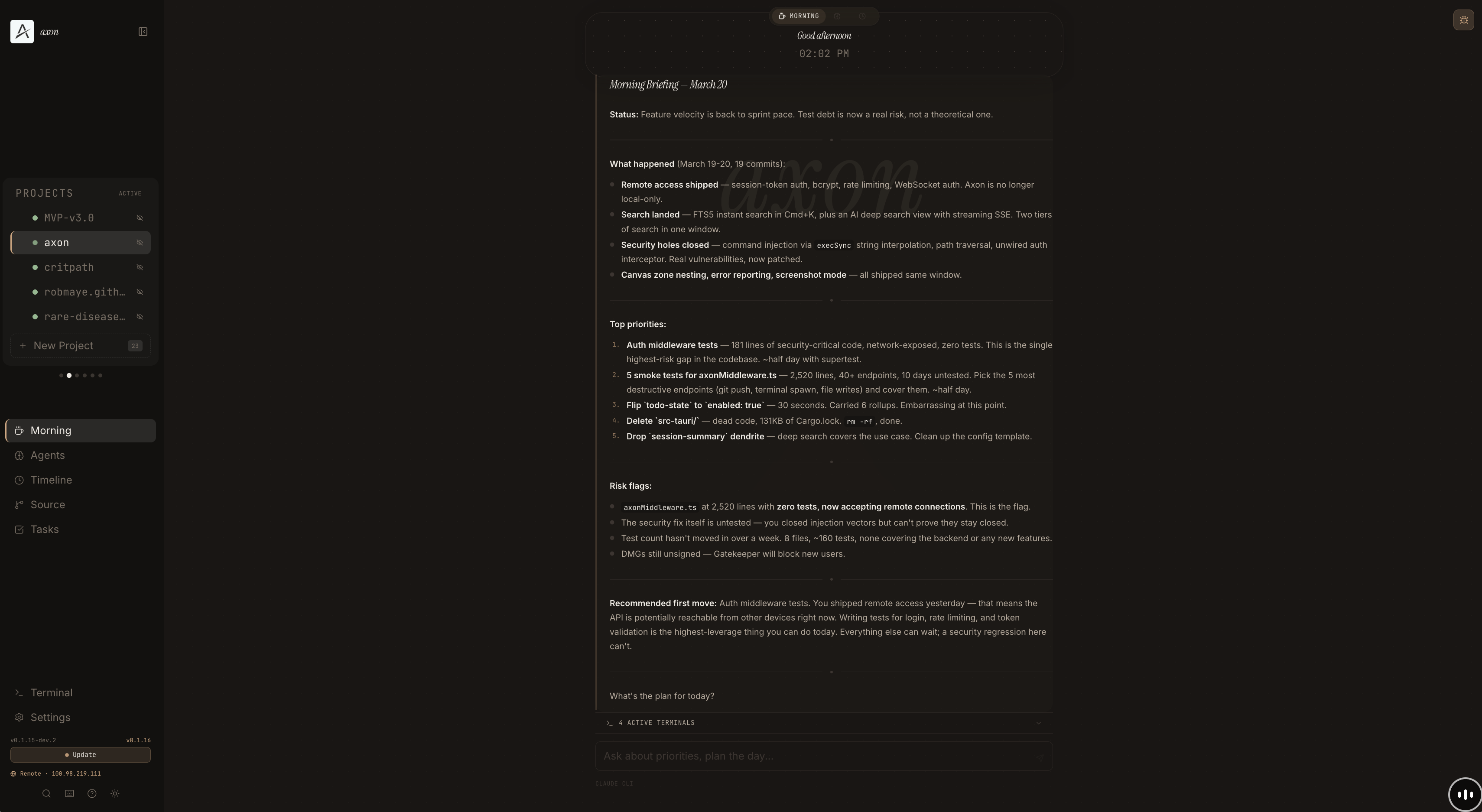
There’s also a desktop app — a morning briefing view, a timeline of rollup cards, and a spatial canvas where all your Claude Code sessions appear as tiles on an infinite pan/zoom workspace. Organise them into zones, click any tile to open a live terminal. The layout is the context.

Where the memory lives
Every tool in this space wants to own your data. Axon stores everything in ~/.axon/ — markdown files with YAML frontmatter. Rollups are markdown. Decision traces, state snapshots — all text. Git-versioned on every rollup, human-readable, portable. In a world of proprietary context windows and platform lock-in, plain text in a directory you own is a radical choice.
~/.axon/workspaces/my-project/
├── state.md # current context snapshot
├── stream.md # append-only raw log
├── episodes/ # nightly rollups
│ └── 2026-03-12_rollup.md
├── dendrites/ # raw input signals
├── mornings/ # briefing conversations
└── config.yaml # project configYou could read your Axon data in twenty years with cat. The archival community has been answering this question for decades: plain text is the gold standard for long-term preservation. You can read a model’s weight tensors easily enough — the formats are open. But you can’t extract what the model knows from those weights. The knowledge is in there somewhere, compressed and entangled, and no one can point to the part that remembers your architecture decision from last Tuesday. WordStar files were recoverable with forensic tools. A decision baked into weights isn’t recoverable by anyone.
Compute is rented — Claude today, something else tomorrow. Your .axon/ directory doesn’t change when you switch models. Look at what happened on OpenAI’s platform: base models get deprecated, fine-tuning APIs get replaced, and then you can’t iterate on your fine-tune — you’re frozen on a stale model while the frontier moves ahead. Even with open weights, your adapter is pinned to that model’s architecture — Llama 3 LoRAs don’t transfer to Llama 5. Maybe retraining gets instant. You still need something to train on.
The rollup step calls Claude’s API — your signals leave your machine for synthesis, the same way they do every time you use Claude Code or any AI tool. But the output lands back in your filesystem as files you own. No platform stores your decision history or project context. If something changes, git diff tells you what and when. Until there’s a step change in model explainability, text is the only medium where verification means reading it. Weights are a black box. Text is a record. An imperfect one — the rollups are AI-synthesised, and synthesis is lossy too. But lossy compression you can read and correct beats lossy compression you can’t see at all. And if lossy AI synthesis weren’t useful, Claude Code wouldn’t exist and I wouldn’t have built Axon with it in three days.
The latest version runs as a server. I have a Mac Mini at home and an M5 MacBook for everything else. The Mini runs Claude Code, hosts all my repos, and accumulates memory. The MacBook is just a browser into it over Tailscale. The server is the product. The laptop is disposable.
Right now this is a schema — a directory convention with a file format. I’m not going to call it a protocol until other people are building on it. But the architecture is designed so that if Axon the product dies tomorrow, the data survives. There’s nothing to migrate away from. It’s markdown in a directory you own.
Why not weights
The default pitch is: put the memory in model weights. Fine-tune an AI on your context, your decisions, your patterns. The memory becomes the model.
Fine-tuning does something real. It encodes behaviour — style, reasoning patterns, decision heuristics. The evidence is clear: post-training adapts existing knowledge rather than encoding new capabilities — a few kilobytes of fine-tuning data can surface behavioural patterns that take gigabytes to learn from scratch. LoRA adapters can add a behavioural layer with minimal degradation to base capability. If you want an AI that reasons like you, fine-tuning is the right tool. These aren’t competing approaches — behavioural alignment and factual memory are different problems.
But developer memory is the factual layer. What was decided, when, by whom, under what constraints, with what alternatives rejected. That’s a retrieval problem, not a training problem. And on retrieval, the evidence is clear: multiple benchmarks show retrieval-augmented generation outperforming fine-tuning on factual recall — particularly for novel and less popular knowledge. If you need to know what happened, retrieve it from a file. If you need to act like someone, fine-tune.
What the labs themselves built: Claude’s memory writes structured text and retrieves it into future sessions. ChatGPT summarises past conversations and injects them as context. Google’s Vertex AI Memory Bank uses external storage queried at inference time. The implementations differ, but the architecture converges: persistent memory lives outside the model, not in weights.
There’s a line of research that could change this. Google’s Titans architecture introduces neural memory that updates its own weights at inference time — real-time learning, not static fine-tuning. NVIDIA’s TTT-E2E compresses long context directly into weights with a 35x speedup at 2M tokens. But even these architectures don’t eliminate the external record. The lossiness problem doesn’t go away — rate-distortion theory shows that a finite compression system will optimally hallucinate with high confidence when memory budget is insufficient. Not a bug, the mathematically correct behaviour for a space-constrained compressor. The verification problem doesn’t go away — if the model memorises your decision in its weights, you can’t check whether it memorised correctly. And model memory stays in the model. Your markdown files don’t.
You still write things down even though you have a brain. The value of the external record was never just recall. It’s that the record exists independently of the system that created it. Your teammate can read it. Your future self using a different model can read it. A file is ground truth. A weight is a compression you can’t audit yet — interpretability is improving, but we’re not close.
And if the market eventually settles on fine-tuning — if model explainability has a breakthrough and weights become truly auditable — you can fine-tune on your Axon files. They’re structured training data whenever you want them to be, and better training data than raw chat logs because they’ve already been synthesised into decision traces with context. The reverse isn’t true. You can’t extract readable decision traces from a fine-tune. Start with the record you can read. Fine-tune later if you want to. The files are the foundation either way.
You can only fork what you can read. You can’t fork weights.

You can't fork classical orgs (eg Microsoft) but you'll be able to fork agentic orgs.
He was talking about organisations, but the principle scales down. That only works if the memory is in files.
The recursive layer
I built Axon using Claude Code. Axon tracks Claude Code sessions.
Claude can write a React component in seconds. It cannot decide whether that component should exist. That gap — between generation and judgment — is what’s still human. Thousands of lines of code in three days, not because I type fast, but because the AI generates fast and I judge fast enough to keep up. For now.
That “for now” is the whole thing. The constraint on productive output is shifting from computational capacity to human cognitive speed. I am the slowest part of my own workflow, and the gap narrows every time the model improves.
That’s a contradiction. The first essay called this an existential threat. This one tries to make it useful. Everyone building in this space right now is holding both — the alternative is paralysis.
Axon is my attempt to make that bottleneck count while it still matters — not by making the human faster at coding, but by compensating for the parts of human cognition that break under load. Attention is rivalrous: you can only focus on one thing, and everything else decays silently. A file with zero tests gets carried for five days not because you ignored it but because you literally couldn’t see it while focused on payments. Memory is self-serving: you don’t recall decisions, you reconstruct them to fit the current narrative. Decision traces are immune to hindsight bias. You’re blind to patterns across time — is this the third sprint where error handling slipped? The rollups make temporal patterns visible that no amount of discipline would surface. Context doesn’t vanish on a cliff, it fades on a curve — by day three you remember the shape but not the constraints. The morning briefing restores full fidelity every time.
An exoskeleton doesn’t think for you. It compensates for structural weaknesses in your body. These cognitive failures aren’t bugs — they’re how brains work. Rivalrous attention, lossy recall, hindsight bias, temporal blindness. No amount of discipline fixes them. The external record does.
Why open source
When AI generates everything, the only proof a human was here is the record of what they rejected. Not what was built — what was judged. Every rollup is that record: what a human directed, approved, rejected, and prioritised during AI-assisted work. It’s narrative provenance. Not oversight infrastructure — that would require tamper-evidence and accountability chains this doesn’t have yet. But something. More than what most AI-assisted development produces today, which is nothing.
I argued two weeks ago that individual solutions to structural problems don’t work. This is an individual solution to a structural problem. I know.
The window for encoding human leverage into AI systems might already be closing. If that’s true, there’s no case for hoarding a developer memory schema. MIT license. Fork it, extend it, build something better.
My MacBook restarted and I lost my terminals. So I built an exoskeleton — not for my body, but for the parts of my cognition that break under load. It writes everything down in files I can read, fork, and hand to someone else. And I built it with the AI that made it necessary.